▣표본 분포
Sampling distribution
표본 분포 (Sampling distribution), 검증분포 , 통계량 분포
- 스튜던트 t-분포 (t-분포, Student's t-distribution)
- F 분포(F -distribution)
- 카이제곱 분포(Χ2분포, chi-squared distribution)
t 분포
t 분포는 정규 분포인 모집단의 모평균을 표본 평균을 통해서 추측할 때 사용되는 분포이다.
표본 평균을 x̄라 두었을 때 확률 변수 x̄를 정규화 하면 아래와 같은 식이 된다.
윗 변에서는 x̄를 x̄의 기대값인 μ로 빼줍니다. 아랫 변에서는 x̄의 표준 편차인 s(n)^1/2로 나누어 줍니다.
(표본 평균의 표준편차)이 때의 s는 표본 표준 편차로 수식은 아래와 같습니다.
(이 둘을 구분하는 것이 다소 헷갈립니다.)
구체적인 유도방식이 궁금하신 분들은 [6]과 [7]을 참고하시기 바랍니다.
\begin{align*} &표본 표준 편차 \quad s=\sqrt{\frac{\sum{(x-\overline{x})} ^{2}}{n-1}}
\\& 표본 평균의 표준 편차 \quad \frac{s}{\sqrt{n}}
\\& 표본 평균의 정규화 \quad \frac{\overline{x}-\mu}{s \sqrt{n}} \sim t(n-1)
\end{align*}
모집단이 정규 분포일 때 표본 평균의 정규화 식은 정규 분포와 유사한 형태를 갖지만 양 끝단에 데이터가 더 많이 분포하는 형태를 띕니다.
정규 분포를 살펴보았을 때, 표준 편차가 더 클 수록 완만한 종 모양을 띈 다는 것을 살펴보았습니다.
마찬가지로 모집단에서 표본을 추출할 경우 표준 편차가 더 커질 것이라는 것을 예상할 수 있다.
이 때문에 곡선의 모양이 더 완만해 지는 것을 t 분포로 설명한다고 이해하면 좋을 것 같습니다.
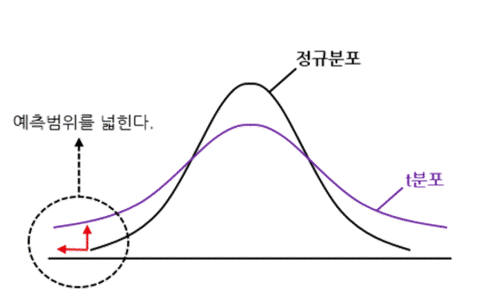
정규 분포의 경우 그래프의 형태를 표준 편차와 평균이 결정하였습니다.
t-분포는 이 둘에 더해 수식 상에서 (n-1)에 해당하는 자유도(degree of freedom)가 그래프의 형태에 영향을 줍니다.
자유도의 정의는 말 그래도 자유스러운 정도로 특정 분포에서 그래프의 모양을 결정하는 모수이다.
대표적으로 t 분포와 카이제곱 분포가 자유도를 모수로 갖습니다.
표본 평균을 구할 때에는 자유도가 n-1인 t-분포를 적용하였습니다.
왜 n-1이 자유도가 될까요? 예를들어 모집단에서 3개의 표본을 추출하여 표본 평균을 구한 결과 5가 나왔다고 해보겠습니다.
가능한 표본은 (5, 5, 5), (3, 5, 7), (1, 5, 9)등이 있다.
여기서 첫 번째 수와 두번째 수에는 어떤 수를 대입하여도 좋지만 마지막 수만큼은 표본 평균을 5로 맞추기 위한 수가 들어가야한다.
즉, 우리가 자유롭게 선택할 수 있는 수의 개수는 2개이므로 자유도가 n-1이 된다.
t 분포 (t Distribution)
- 자유도가 커지고 n=80 이면 정규분포에 근접한다.
Sample의 표준 편차와 표의 비교
t(α , 𝜙)= t(0.05 , 8)= 1.860
카이제곱분포
카이제곱분포는 k개의 독립적이고 표준 정규분포를 따르는 확률 변수들의 제곱의 합이 갖는 분포이다.
카이제곱분포의 수식과 그래프는 아래와 같습니다.[8]
\begin{align*} &Q=\sum_{i=1}^k {X_i}^2
\\& Q \sim {x_k}^{2} \end{align*}
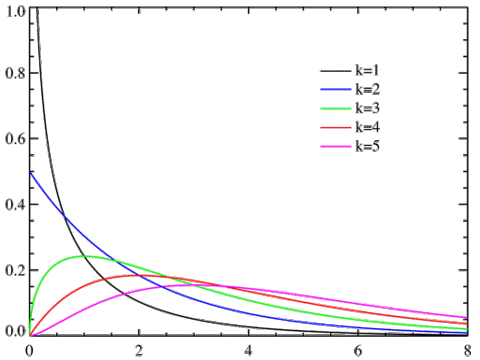
카이제곱분포의 수식은 굉장히 단순한다. 단순한 만큼 응용되는 분야도 다양한다.
모분산에 대한 추론, 카이제곱검정 등에서 사용된다.
카이제곱검정은 별도의 포스팅에서 다뤄보도록 하고,
모분산의 추론 시에 카이제곱분포가 어떻게 활용되는지만 가볍게 살펴보고 넘어가도록 하겠습니다.
먼저 표본 분산을 수식으로 표현하면 아래와 같습니다.
$$$ s^{2}= \frac{\sum_{i=1}^k ({x-\overline{x}})^2}{n-1} $$$
모분산을 살짝 변형한 아래 수식이 자유도가 n-1인 카이제곱 분포를 띈다고 하며,
이를 이용하여 모분산을 추정한다고 한다.
$$$ \frac{(n-1)S^{2}}{\sigma^{2}}\sim x_{(n-1)}^2 $$$
카이제곱분포를 유도하는 과정이 교과서에서도 생략되어 있어서 추가적으로 조사한 내용을 첨부한다.
저는 사실 읽어봐도 완전히 이해가 가지 않는 부분이 있는데 그러려니 하고 넘어갔습니다.
f-분포
f-분포는 두 확률 변수 V1, V2가 각각 자유도가 k1, k2이고 서로 독립인 카이제곱 분포를 따른다고 할 때
형성하는 분포로 수식과 그래프는 아래와 같습니다.
$$$ \frac{V_1 / k_1}{V_2 / k_2} \sim F_{k_1, k_2} $$$
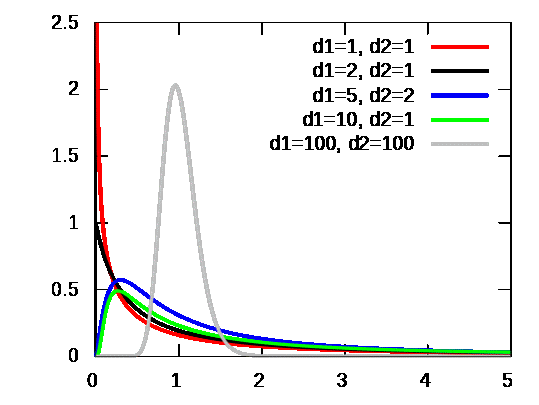
f-분포는 f 검정이나 분산 분석에서 많이 활용된다고 한다.
예를들어 앞서 카이제곱 분포가 모분산의 추정에 사용되었습니다면 f-분포는 두 모분산의 비율에 대한 추정을 할 ? 사용된다.
수식으로 표현해보면 아래와 같습니다.
$$$ \frac{S_2^2 \sigma_1^2}{S_1^2 \sigma_2^2} \sim F_{n_2 -1, \; n_1 -1 } $$$
F 분포는(F Distribution.)
F 분포는 정규 분포의 분산 비율을 계산하려고 할 때 적절한다.
Ex1)μ = 50σ2= 102
Sample : #1 기계
μ1 = 103, 91, 102, 98, 100, 101 , 107 , 103, 97 s1 = 4.54
μ2 = 101, 100, 100, 97, 96, 102 s2 = 2.33
$$$ F\ =\frac{S_1^2}{S_2^2}\ \ =\frac{S_1^2}{S_2^2} $$$
$$$ = \frac{{4.54}^2}{{2.33}^2}=3.79 F(8 , 5, 0.05)= 4.82 9 (같다)$$$
m=50.33 σ = 4.96
$$$ Χ2=n-1S2σ2 = 6-14.962102 = 1.23 $$$
Χ2표에서 자유도 5 .Cf : 0.99 0.554(다르다고 할 수 없다.)
감마 분포
감마 분포와 베타 분포를 이해하기 위해서는 먼저 감마 함수와 베타 함수를 이해해야 한다.
먼저 감마 함수를 설명드리겠습니다. 감마 함수는 팩토리얼의 개념을 함수로 일반화하여 표현한 것이다.
감마 함수에 대한 보다 자세한 내용은 다음의 자료를 참고하시면 된다.[10]
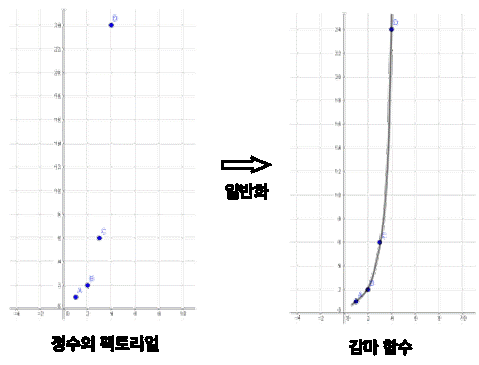
감마 함수의 수식과 대표적인 성질을 수식으로 표현하면 아래와 같습니다.
$$\begin{align*} & \Gamma(z)=\int_{0}^{\infty}a^{z-1}a^{-t}dt \quad (Re \quad z \gt 0)
\\& \Gamma(n)=(n-1)! \end{align*}$$
감마 함수에 정수 n을 입력으로 넣으면 (n-1)!를 결과로 얻습니다.
또한 그동안 정수에 머물러 있었던 팩토리알을 복소수 차원으로 확장시켜 주었다고 한다.
감마 함수를 실수축 위에 그려보면 아래와 같습니다.
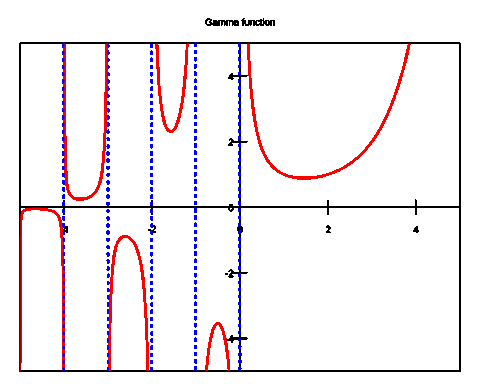
감마 분포는 감마 함수를 응용하여 유도할 수 있다.
유도 방식은 다음의 자료를 참고해주시면 되며[12] 구체적인 수식과 그래프는 아래와 같습니다.
여기서 k와 θ는 감마 분포의 모수(parameter)이며 k는 그래프의 모양(shape)를, θ는 그래프의 크기를 결정한다고 한다.
$$$ f(x,k,\theta)=x^{k-1}\frac{e^{-x/\theta}}{\theta^k \Gamma(k)} \quad for \quad x \gt 0 $$$
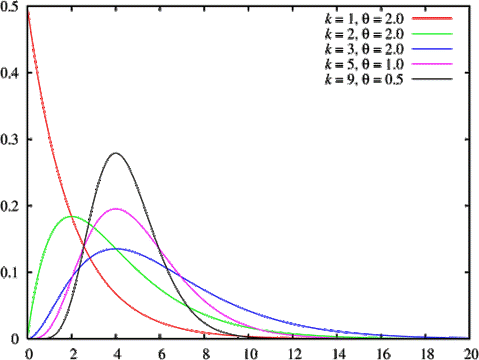
감마 분포는 k번째 사건이 일어날 때까지 걸리는 시간에 대한 연속 확률분포라고 한다.
즉, 총 k번의 사건이 발생할 때까지 걸리를 시간의 확률 분포로 이해하면 좋을 것 같습니다.
베타 분포
베타 분포를 이해하기 위해서는 마찬가지로 베타 함수에 대해서 이해해야 한다.
감마 함수가 팩토리알을 일반화하는 함수였다면
베타 함수는 이항 계수(binomial coefficient)를 일반화 한 함수로 이해할 수 있다.
이항 계수는 n개 중에 k개를 뽑을 수 있는 조합의 수로 nCk로 흔히 알고 있다.
이항 계수를 수식으로 표현하면 아래와 같습니다.
\begin{cases}
n! / (k!(n-k)!)& 0 \leq k \leq n
\\ 0 & k \lt 0
\\ 0 & k \gt n
\end{cases}
이항 계수 역시 기존에는 자연수에 대해서만 정의가 되어 있었습니다.
이를 일반화한 것이 베타 함수이며 수식과 그래프로 표현하면 아래와 같습니다.
(그래프를 찾긴 했으나 이해를 하진 못했습니다)
\begin{align*} & \beta(x,y)=\int_{0}^{1} t^{x-1}(1-t)^{y-1}dt \quad (Re \; x \gt 0, \quad Re \; y \gt 0)
\\& \left(\begin{array}{c} n\\ k\end{array}\right)=\frac{1}{(n+1)\; \beta \; (n-k+1, k+1)}
\end{align*}
이는 앞서 살펴본 감마 함수와 밀접한 연관이 있다.
이항 계수가 사실은 팩토리알로 이루어져있습니다는 사실을 떠올려보면 베타 함수를 감마함수로 표현할 수 있습니다는 것을
이해할 수 있다.
$$$ \beta(x,y)=\frac{\Gamma (x)\Gamma (y)}{\Gamma (x+y)} $$$
이제 베타 분포로 넘어가보도록 하겠습니다.
베타 분포는 두 개의 매개 변수에 의해서 형태가 결정되며 수식과 그래프는 아래와 같습니다.
$$$ \beta(x; \alpha, \beta)=\frac{\Gamma (\alpha + \beta)}{\Gamma (\alpha)\Gamma (\beta)}x^{\alpha-1}(1-x)^{\beta-1} $$$
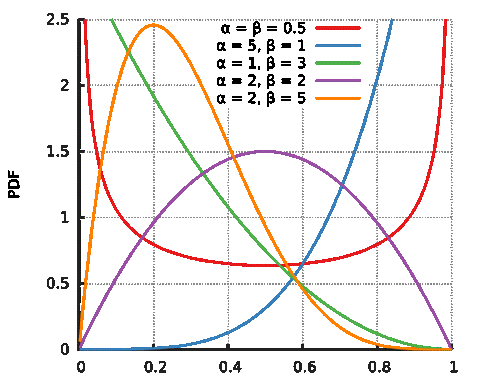
이러한 베타 분포는 전통적인 강화학습이나 베이지안 추론에서 자주 등장한다고 한다.
이들을 별로도 다룬 포스팅에서 베타 함수가 어떻게 현실에 적용되는지 살펴볼 수 있도록 하겠습니다.
ps. 감마 분포와 베타분포는 수학적 배경지식이 부족하여 완벽히 이해를 못하고 넘어가는 아쉬움이 있다.
추후에 더 공부하여 이해한 내용이 있습니다면 쉽게 풀어서 내용을 추가하도록 하겠습니다.
공분산과 피어슨 상관계수
들어가며
캐글 컴페티션 같은 데이터 사이언스 테스크를 풀 때 주어진 데이터의 특성을 분석하는 작업을 EDA라고 한다.
EDA를 수행할 때 필수적으로 분석하는 것이 자료들 간의 상관관계입니다
가령 직원들의 근무 성과 데이터가 주어졌다고 하면 직원들의 거주 지역과 성과 사이의 상관관계를 분석하고 싶을 수 있다.
만일 상관관계가 높다면 직원들의 성과를 예측하는데 적절한 데이터로 활용이 가능하겠죠?
이렇듯 데이터 간의 상관관계를 분석하고 싶을 때 사용되는 것이 공분산이다.
이번 포스팅에서는 공분산의 기초 개념과 실질적으로 많이 사용되는 피어슨 상관 계수에 대해서 알아보겠습니다.
공분산(covariance)
공분산은 두 측정값 사이에 연관성을 분석하기 위해서 사용하는 통계 지표이다.
분산은 아시다시피 집단 안에서 자료들이 얼마나 흩어져 있는가를 측정하는 값으로 개별 값에 평균을 빼준 뒤 제곱한 값들을 모두 더한 다음,
자료의 수로 나누어준 값이다.
이제 서로 다른 두 자료 집단 간에 상호 연관성을 분석하기 위해서 공분산의 개념을 알아보겠습니다.
수식은 아래와 같습니다.
\begin{align*} & \sigma_{xy}=\frac{1}{nd}\sum_{i=1}^N (x_i - \mu_x)(y_i - \mu_y)
\\& \sigma_{xy} \gt 0 : X 와 Y가 양의 선형 관계
\\& \sigma_{xy} \lt 0 : X 와 Y가 음의 선형 관계
\\& \sigma_{xy} = 0 : X 와 Y가 양의 선형 관계
\end{align*}
위 식은 x와 y의 모집단을 대상으로 측정한 모집단 공분산이다.
만일 n개의 표본만 추출하여 공분산을 측정하였습니다면 표본 공분산이라 부르며 수식이 살짝 달라집니다.
$$$ S_{xy}=\frac{\sum_{i=1}^n (x_i-\overline{x})(y_i-\overline{y})}{n-1} $$$
n으로 나눠주는 것이 아닌 n-1로 나눠주는 것은 n-1로 나눠주어야만 비편향 추정량이 되기 때문이라고 한다.
n-1로 나눠주는 이유는 표본 분산이 비편향 추정값이 되도록 하기 위함인데,
자세한 내용은 다음의 자료를 참고해주시 바랍니다.[2]
피어슨 상관 계수(Pearson Correlation coefficient)
두 숫자형 변수 사이의 선형적 강도를 나타내기 위해서 공분산을 그대로 사용하지 않고,
공분산을 각 변수의 표준 편차로 나누어준
피어슨 곱적률 상관계수(Pearson product moment correlation coefficient)를 많이 사용한다.
식으로 나타내면 아래와 같습니다.
$$$ \rho_{xy}= \frac{\sigma_{xy}}{\sigma_x \sigma_y} $$$
이 피어슨 상관계수는 -1에서부터 1 사이의 값을 가집니다.
공분산과 마찬가지로 양수일 경우 두 변수가 양의 선형 상관 관계, 음수일 경우 음의 선형 상관 관계,
0일 경우 선형적 관계가 존재하지 않습니다.
이러한 피어슨 상관 계수에 따른 두 자료의 분포를 시각화해보면 아래와 같습니다.
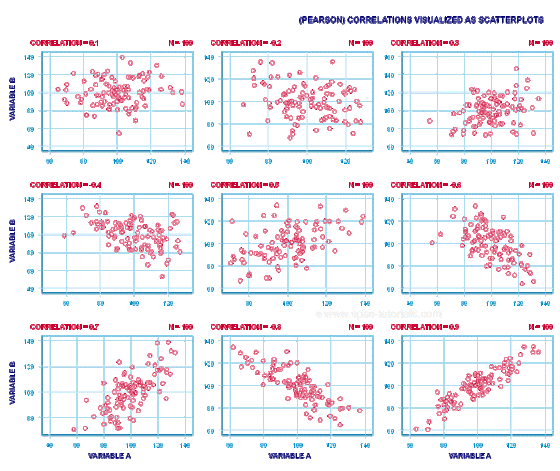
그래프 상에서 하나의 점은 x좌표와 y좌표를 가지며 각각은 확률 변수이다.
점의 개수는 표본의 개수 n에 해당한다. 좌측 상단에 그래프를 보면 상관계수가 0.1이다.
이 경우 점들이 특정한 패턴을 가지지 못하고 흩어져 있게 된다.
반면 우측 하단의 그래프는 0.9로 양의 상관관계가 높습니다.
이는 곧 x 값이 증가할 때 y값도 함께 증가하는 선형 관계를 가짐을 의미하며, 점들이 우상향 직선 형태를 만들며 모여있게 된다.
바로 옆 중앙 하단 그래프의 경우에는 음의 선형관계를 가져서 반대 방향의 직선 그래프를 보여줍니다.
피어슨 상관 계수의 활용
도입부에 언급했듯이 피어슨 상관 계수는 데이터 사이언스에서 실용적으로 많이 활용된다.
캐글의 유명한 타이타닉 데이터 셋을 통해서 이것이 어떻게 활용되는지 알아보겠습니다.
먼저 데이터 셋은 다음과 같이 구성되어 있다.
승객 별로 생존 여부와 이름, 성별, 형제 자매와의 동승 여부, 부모 자식들의 동승 여부, 지불한 금액 등등의 정보가 나와있다.
이렇게 데이터만 봐서는 생존 여부에 어떠한 지표가 가장 상관관계가 높을지 가늠이 안된다.
이를 pandas-profiling을 활용하여 각 컬럼별 피어슨 상관관계를 구해보았습니다.
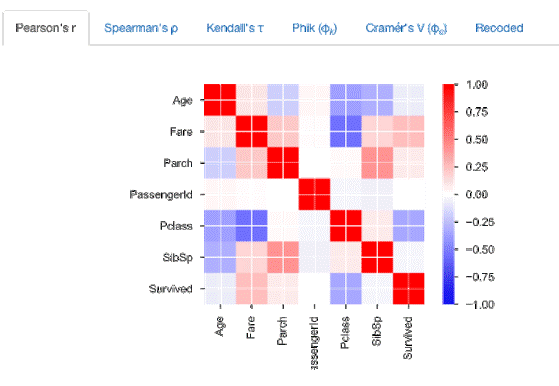
붉은 색으로 표시될 수록 피어슨 상관관계가 높은 것이며,
x축과 y축에는 각각의 컬럼명이 있다.
먼저 자기 자신과는 항상 상관관계가 1이므로 붉게 표시된 것을 확인할 수 있다.
다음으로 눈에 띄는 것은 생존 여부를 나타내는 Survived와 Fare가 붉게 표시되어 있다.
즉, 부자일 수록 생존 확률이 높다는 것을 유추할 수 있다.
반면 Pclass와 Fare 사이에는 음의 상관관계가 나타났는데
지불한 금액이 낮을 수록 낮은 등급의 좌석에 탑승하게 되므로 당연한 결과라고 볼 수 있다.
이렇든 컬럼간의 상관관계를 피어슨 상관관계를 통해서 파악해보면 데이터의 특성을 한 눈에 파악 가능한다.
또한 피쳐 엔지니어링을 수행할 때 많은 도움이 된다.